> For the complete documentation index, see [llms.txt](https://docs.secoda.co/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://docs.secoda.co/best-practices/clean-up-your-data.md).
# Clean up your data
Secoda has built-in tools designed to streamline the process of data cleanup, enhancing the overall health of your data environment. This guide will explore how you can leverage these tools to improve data quality, enhance security, reduce storage costs, and boost productivity.
{% hint style="info" %}
Make sure you check the [lineage graph](/features/data-lineage.md) in Secoda before deprecating a resource in the source!
{% endhint %}
## Key benefits of effective data cleanup
* **Efficient Resource Management:** Quickly identify underutilized data, reducing time spent on manual checks.
* **Enhanced Data Quality and Security:** Improve the accuracy and protectiveness of your data assets.
* **Increased Analyst Productivity:** Ensure analysts have access to relevant and reliable data.
* **Cost Reduction:** Decrease expenses associated with storing outdated or unused data.
## Features for cleaning up your data
### Access [Popularity](/features/popularity.md) metadata
* Utilize the Popularity metadata to determine which data resources are least accessed.
* Sorting the Catalog by Popularity helps identify candidates for deprecation based on minimal views or queries.
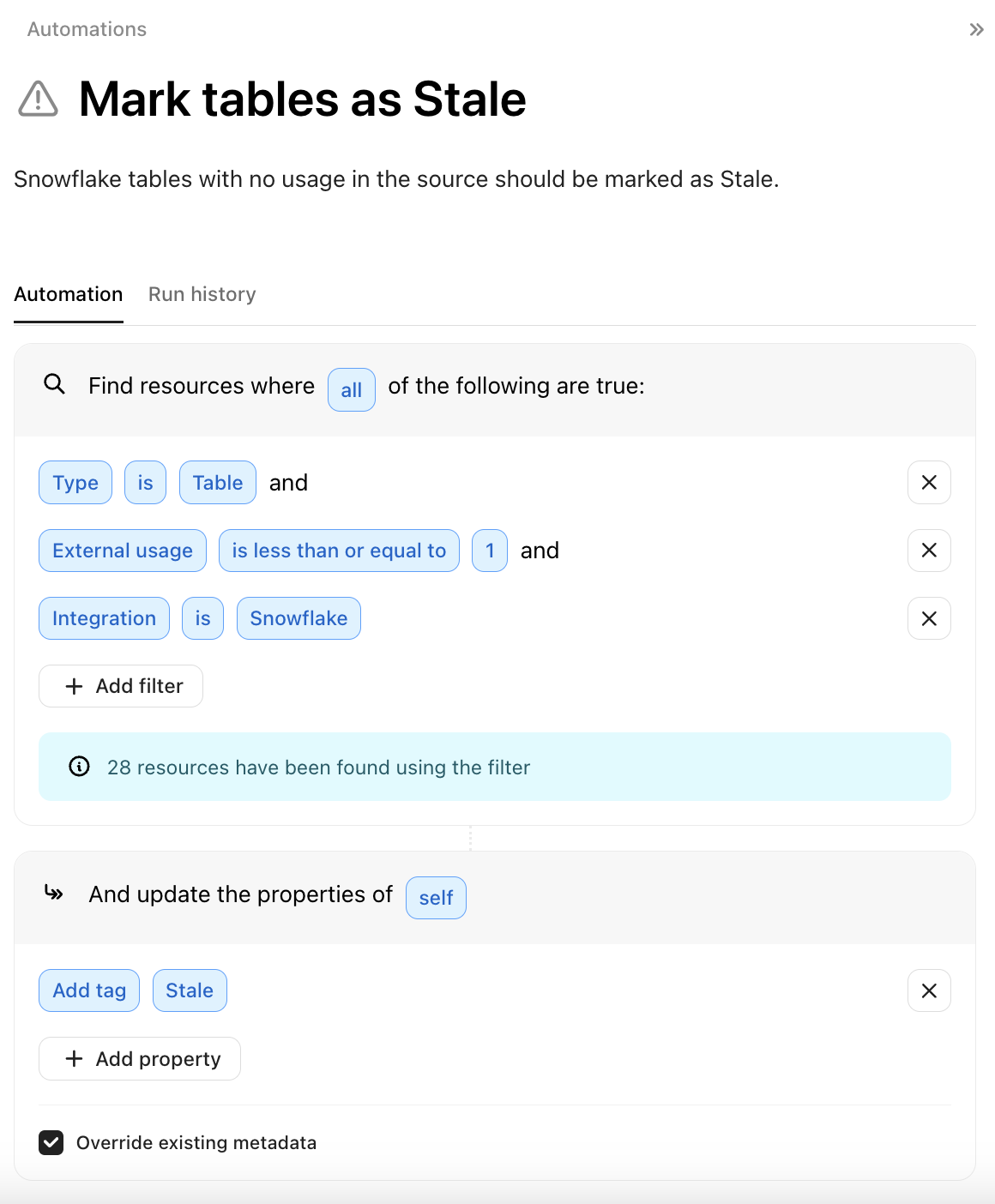
### [Automations](/features/automations.md) to identify stale assets
* Set up Automations to tag resources that haven’t been accessed or updated within a specific timeframe as "Stale" or "Candidates for Deprecation."
* Consider adding a property to the Automation to push these to a private Team or specific Collection, if that's helpful for review purposes.
* Then, filter the Catalog by these tags to manage these resources efficiently!
### [Use cases](/features/monitoring/monitoring-use-cases.md)
* Implement Cardinality or Unique Percentage Monitors on essential data resources.
* Alerts from these monitors can indicate duplicates or other data quality issues, prompting cleanup actions.
{% hint style="info" %}
[Secoda’s API](https://github.com/secoda/gitbook/blob/master/best-practices/broken-reference/README.md) extends the functionality of the above features, enabling programmatic management of data cleanup tasks. If you require assistance with the API, the [Secoda Community Slack](https://via.intercom.io/c?url=https%3A%2F%2Fjoin.slack.com%2Ft%2Fsecodacommunity%2Fshared_invite%2Fzt-mhnu278g-FktKZmZ51SDQtlu3NRAxqg\&h=13f5aaa171821956434fc25f4c759a803f98a84f-dssmg53d_11:24933\&l=d215b12164c764d92e3bca464c2434cae72f7a22-8270396) is available for support.
{% endhint %}
## Cost containment resources
* Articles:
* [Data Stack Cost Management Best Practices | Secoda](https://www.secoda.co/blog/managing-costs-of-the-modern-data-stack-at-scale)
* [How To Increase the ROI of Your Data Team | Secoda](https://www.secoda.co/blog/from-cost-center-to-revenue-generator-unleashing-the-potential-of-data-teams)
* [4 ways to improve data quality | Secoda](https://www.secoda.co/blog/4-ways-to-improve-data-quality)
* Webinar: [Mastering cost containment for modern data teams](https://www.youtube.com/watch?v=1R8y8LZRJCU)
* [Snowflake Costs](/integrations/data-warehouses/snowflake-integration/snowflake-costs.md)
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://docs.secoda.co/best-practices/clean-up-your-data.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.